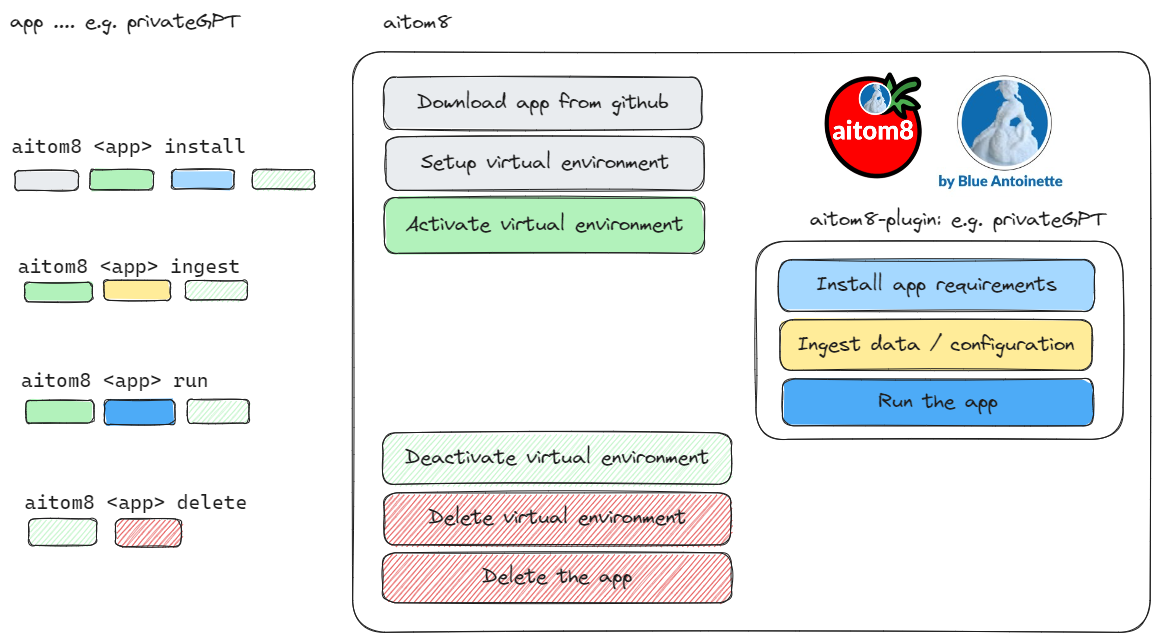
Learn how you can compose a fully functional LangChain app without writing a single line of code. We demonstrate this live in this YouTube video by utilizing the latest release of our AI automation software aitom8.
You can get aitom8 here:

Auto-generated Python Code (Sample: HuggingFace Pipeline)
app.py
#!/usr/bin/env python3
# Basic libraries
from dotenv import load_dotenv
import os
# Required for LangChain prompts and llm chains
from langchain import PromptTemplate, LLMChain
# Required to load the model via local HuggingFace Pipelines
from huggingface.pipeline.transformer import loadModel
# Alternative:
# from huggingface.pipeline.parameter import loadModel
# Load environment variables from .env file
load_dotenv()
def create_prompt(question : str, llm : str):
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
print(llm_chain.run(question))
def main():
llm = loadModel(model_id="bigscience/bloom-1b7")
#llm = loadModel(model_id="OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
create_prompt(question="What is the capital of France?", llm=llm)
if __name__ == "__main__":
main()
huggingface.pipeline.transformer
#!/usr/bin/env python3
# Required for Langchain HuggingFace Pipelines
from langchain import HuggingFacePipeline
# Required for direct HuggingFace Pipelines
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
def loadModel(model_id : str) ->any:
llm = HuggingFacePipeline(pipeline=getTransformerPipeline(model_id))
return llm
def getTransformerPipeline(model_id : str) ->pipeline:
match model_id:
case "bigscience/bloom-1b7":
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# device_map: -1...use CPU, 0...use first GPU, ..., "auto"...use all GPUs
device_map="auto"
transformerPipeline = pipeline(
"text-generation", model=model, tokenizer=tokenizer, max_new_tokens=18, device_map=device_map
)
case _:
print("No pipeline available for model: " + model_id)
exit()
return transformerPipeline
Need further support or consulting?
Please checkout our Consulting hours.